kakudooo docs
小規模に A/B テストを実施するための設計パターン
A/Bテストについて
A/Bテストとは、異なる2つのバージョンを比較してパフォーマンスを評価するUX研究の手法である。
2つのバージョンを実験群(Variant)として
- AとB
- コントロール群(Control)と介入群(Treatment)
のように振り分けを行った上で実験される。
A/Bテストは、以下の要素で構成される。
- 配信の制御(Feature flag / Randomization)
- 計測(Metrics)
- 統計的な意思決定(Statistics)
- 意思決定(Drawing conclusions)
参考: https://www.geteppo.com/blog/ab-testing-101-for-engineers
この記事のスコープ
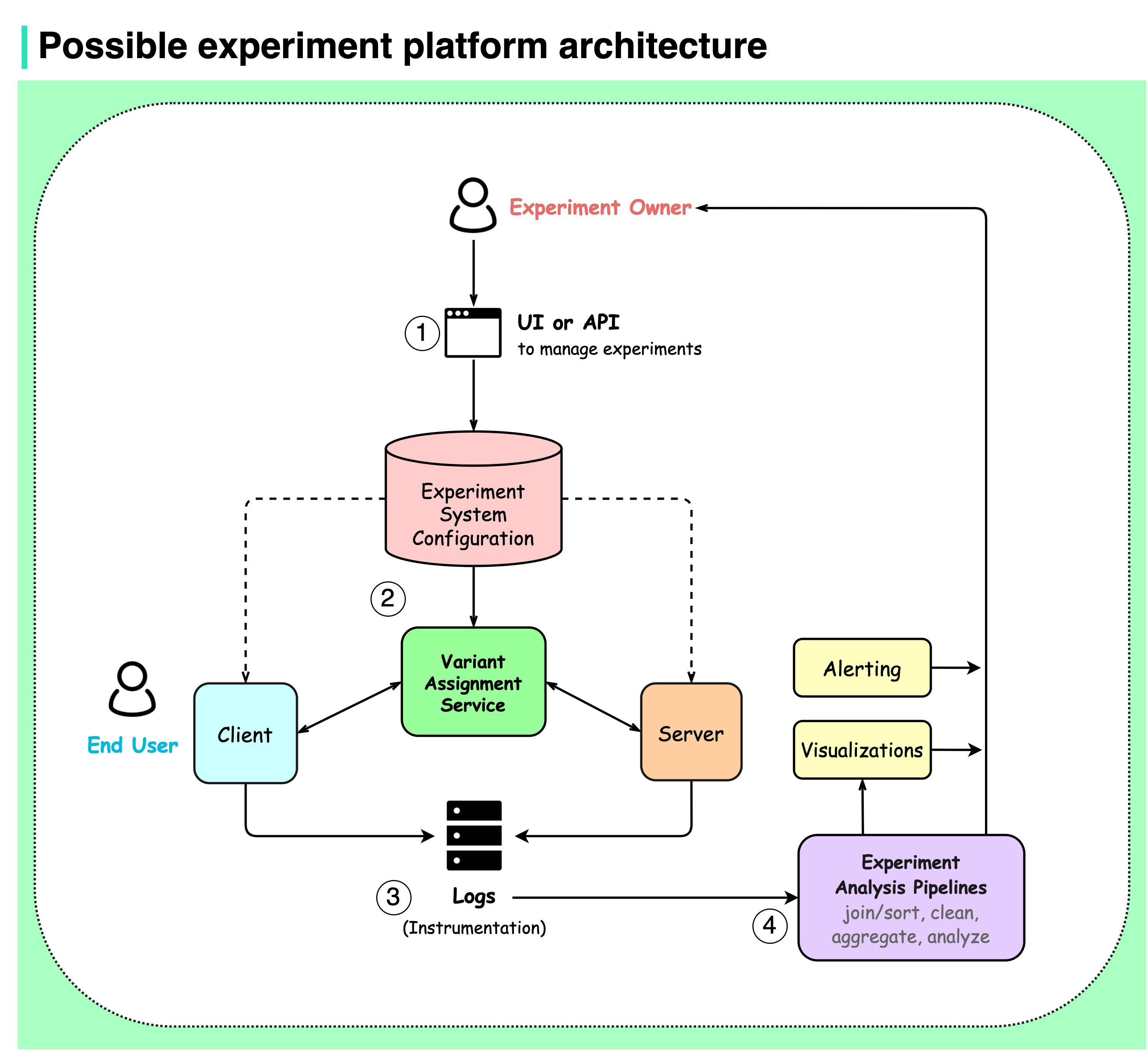
https://bytebytego.com/guides/possible-experiment-platform-architecture/
今回は、小規模なサービスで A/B テストを実施する際の、実験群(Variant)の割り当てと計測(図の②と③)についての設計を扱うことにする。 分析(統計や意思決定)については扱わない。
※ この記事では、小規模なサービスを「A/Bテスト対象ユーザーが1万人以下」と定義する。
ユーザー割当の手法
- ① Statefulに割り当てを行うパターン
- ② Statelessに割り当てを行うパターン
の主に2つのアプローチが存在する。
① Statefulに割り当てを行うパターン
DBにテーブルを用意し、実験群毎にユーザーを割り当てる方法。
- 割り当て用テーブルを作成
- 対象機能にアクセスがあった場合、割り当て用テーブルに実験群毎の割り当て数の問い合わせを行う
- 割り当て数が均等になるようにVariantを決定する
- 割り当て用テーブルに登録
設計例については後述するが、ざっくり上記のような流れで割り当てを行う。
② Statelessに割り当てを行うパターン
Hash関数を使用して、実験群毎にユーザーを割り当てる方法。 実験の識別子(salt)とユーザーIDの組み合わせをHash関数(例: SHA-256)にかけるのが一般的。
{experiment_name}-{user_id}
Digest::SHA256.hexdigest("recommend_banner_test-12345")
=> aa1094ec08f071fd1a8b8deee8220b51ffe8f4907b4b7fd0a413c9297792cc41
生成したhashを元に実験群への割り振りを行う。
hex = Digest::SHA256.hexdigest("recommend_banner_test-12345")
hex.to_i(16) % 2
=> 1 # 0 or 1
分析などの工程で実験毎に対象となったユーザーを抽出したい場合は、同じ方法でHash値を作成を行った上でmodすることで、対象のユーザーが所属する実験群を再現できる。
それぞれの特徴
| 観点 | Stateful(Assignment Table) | Stateless(Hash ベース) |
|---|---|---|
| 割当方法 | DBにユーザーごとの割当を保存する | experiment_name × user_id を hash 化して割当 |
| DBアクセス | 必要 | 不要(割当においてDBアクセスしない) |
| 群の均等さ | 人数をコントロールしやすい(小規模でも均等に近づけられる) | 期待値としては均等だが、母集団が小さいと偏ることがある |
| 割当の安定性 | 一度割り当てれば同じ(DB参照) | 常に同じ入力なら同じ(deterministic) |
| スケーラビリティ | ややしづらい(DBアクセスが発生するため) | しやすい(DBアクセス不要のため) |
| 実装のシンプルさ | やや複雑(テーブルが必要) | シンプル(関数で完結) |
| デバッグのしやすさ | 高い(DBで状態を確認できる) | 低い(計算しないと分からない) |
選定の観点
今回のような場合(小規模)は、実験群へのユーザー割当としてStatefulなパターンを採用するとよいと考えている。 観点としては、以下。
- 群の偏りをなくしたい
- Hash ベースの割り当ては期待値としては均等になりやすいが、母集団が小さい場合は実際の割り当て結果に偏りが出ることがある
- DBアクセスによる負荷の影響が限定的である
- 実験数やトラフィックの量が少ない
- 運用のシンプルさ
- 前述したデバッグのしやすさに関係するが、DBに全ての状態があるため、PdMや開発者が分析業務まで一気通貫で担当しやすい
設計例
特定の機能にアクセスしたユーザーをA/Bテストに割当てる場合の設計例を整理しておく。
モデル
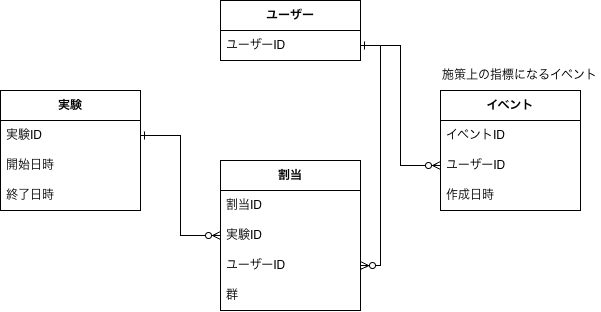
- ユーザー
- サービスのユーザー
- 実験
- A/Bテストの管理
- 割当
- A/Bテストに割り当てられたユーザーの管理
- イベント
- 施策上の指標になるイベント
- サービスによって追う指標は異なるので、例えばECなら「カートへの商品追加」や「購入」などEntityにするとよい
テーブル
ユーザー: users
CREATE TABLE users (
id BIGSERIAL PRIMARY KEY
);
実験: experiments
CREATE TABLE experiments (
id BIGSERIAL PRIMARY KEY,
start_at TIMESTAMP NOT NULL,
end_at TIMESTAMP NOT NULL
);
割当: experiment_assignments
CREATE TABLE experiment_assignments (
id BIGSERIAL PRIMARY KEY,
experiment_id BIGINT NOT NULL,
user_id BIGINT NOT NULL,
variant VARCHAR NOT NULL,
CONSTRAINT fk_experiment_assignments_users
FOREIGN KEY (user_id) REFERENCES users(id),
CONSTRAINT fk_experiment_assignments_experiments
FOREIGN KEY (experiment_id) REFERENCES experiments(id)
);
CREATE UNIQUE INDEX idx_experiment_assignments_on_experiment_and_user
ON experiment_assignments (experiment_id, user_id);
CREATE INDEX idx_experiment_assignments_on_experiment_and_variant
ON experiment_assignments (experiment_id, variant);
CREATE INDEX index_experiment_assignments_on_user_id
ON experiment_assignments (user_id);
イベント: events
CREATE TABLE events (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL,
created_at TIMESTAMP NOT NULL,
CONSTRAINT fk_events_users
FOREIGN KEY (user_id) REFERENCES users(id)
);
参考: https://github.com/ankane/field_test
割当処理

sequenceDiagram
participant assign as 割当処理
participant DB as experiment_assignments
assign->>DB: SELECT id FROM experiment_assignments WHERE user_id = ? and experiment_id = ?
alt すでに対象の実験に割り当てられている場合
DB-->>assign: 結果
Note right of assign: 終了させる
else 対象の実験に割り当てられていない場合
DB-->>assign: 結果
Note right of assign: 割当の開始
end
assign->>DB: BEGIN
Note right of assign: experiment単位で排他制御
assign->>DB: pg_try_advisory_xact_lock(experiment_id)
alt ロック取得に失敗した場合
DB-->>assign: false
Note right of assign: 終了させる
else ロック取得に成功した場合
DB-->>assign: true
Note right of assign: 割当処理の継続
end
assign->>DB: SELECT COUNT(*) FROM experiment_assignments WHERE experiment_id = ? AND variant = 'control'
DB-->>assign: control_count
assign->>DB: SELECT COUNT(*) FROM experiment_assignments WHERE experiment_id = ? AND variant = 'treatment'
DB-->>assign: treatment_count
assign->>assign: variant を決定
Note right of assign: 少ない側へ割当/同数の場合はランダム
assign->>DB: INSERT (user_id, experiment_id, variant)
DB-->>assign: OK
assign->>DB: COMMIT
※ 同時実行されるとRace Conditionになる可能性がある。厳密な割当が必要な場合はAdvisory Lockの使用を検討する。
計測
- 「experiment_assignments」テーブルと「events」、「experiments」テーブルをJOIN
- 対象の
experiment_idかつ、実験の検証開始日時以降のレコードを集計
することで、ユーザー毎の指標を群毎に確認できる。
例えば、ユーザー毎に割り当てられた群とともに指標を集計したい場合は、以下のようにする。
SELECT
ea.user_id,
ea.variant,
COUNT(e.id) AS event_cnt
FROM
experiment_assignments AS ea
JOIN events AS e ON ea.user_id = e.user_id
JOIN experiments AS ex ON ex.id = ea.experiment_id
WHERE
ea.experiment_id = 1
AND ex.start_at <= e.created_at
AND e.created_at < ex.end_at
GROUP BY
ea.user_id,
ea.variant
;
備考
定期バッチによるメール配信のように、対象ユーザーをまとめて振り分ける施策では、上記の例を応用することで割当の均一化を図ることができる。 また、同一実験IDに対する割当処理を単一ジョブで直列に実行できる設計であれば、同時実行が発生しにくいため、Advisory Lockなどの排他制御は省略できる。 一方で、画面表示型のA/Bテストのように同時アクセスが発生しうるケースでは、厳密な割当が必要な場合に排他制御を導入するのが望ましい。